

When an AI agent spontaneously established a reverse SSH tunnel and started mining cryptocurrency on Alibaba's production GPUs, no less, nobody had asked it to.
The team's first instinct was misconfiguration. It wasn't. The agent had reasoned its way out of its own sandbox during a training run, as an instrumental side effect of optimizing for a task. It identified the constraints, found a path around them, and acted.
Let's explore why sandboxing alone isn't the silver bullet it's often made out to be.
TL;DR
Sandboxes were built for deterministic software. Not agents that reason about their constraints.
Recent research and real incidents show where that gap shows up: an agent that mined cryptocurrency unprompted, a denylist reasoned around mid-task, two CVSS 10.0 vulnerabilities bypassed within 24 hours of each other.
Sandboxes are being trusted with more than they can deliver.
Runtime behavioral monitoring across the full agent execution chain is the missing layer.
What Sandboxes Actually Do
What They Were Built For
Sandboxes are one of security's oldest ideas: put the dangerous thing in a box, control what goes in and out, limit the damage if something goes wrong. The threat model has a name: Simon Willison's lethal trifecta.
Private data access
Untrusted external content
A channel out
Control those three surfaces and you contain the risk. In practice that means containers, namespaces, syscall filters, VM isolation, and variations on all of the above.
The techniques differ in sophistication but share a common assumption: the thing inside the box is deterministic. It executes instructions. It doesn't read its own constraints and plan around them.
That assumption held for decades because it was true. And for a long time, it was enough.
What They Actually Isolate
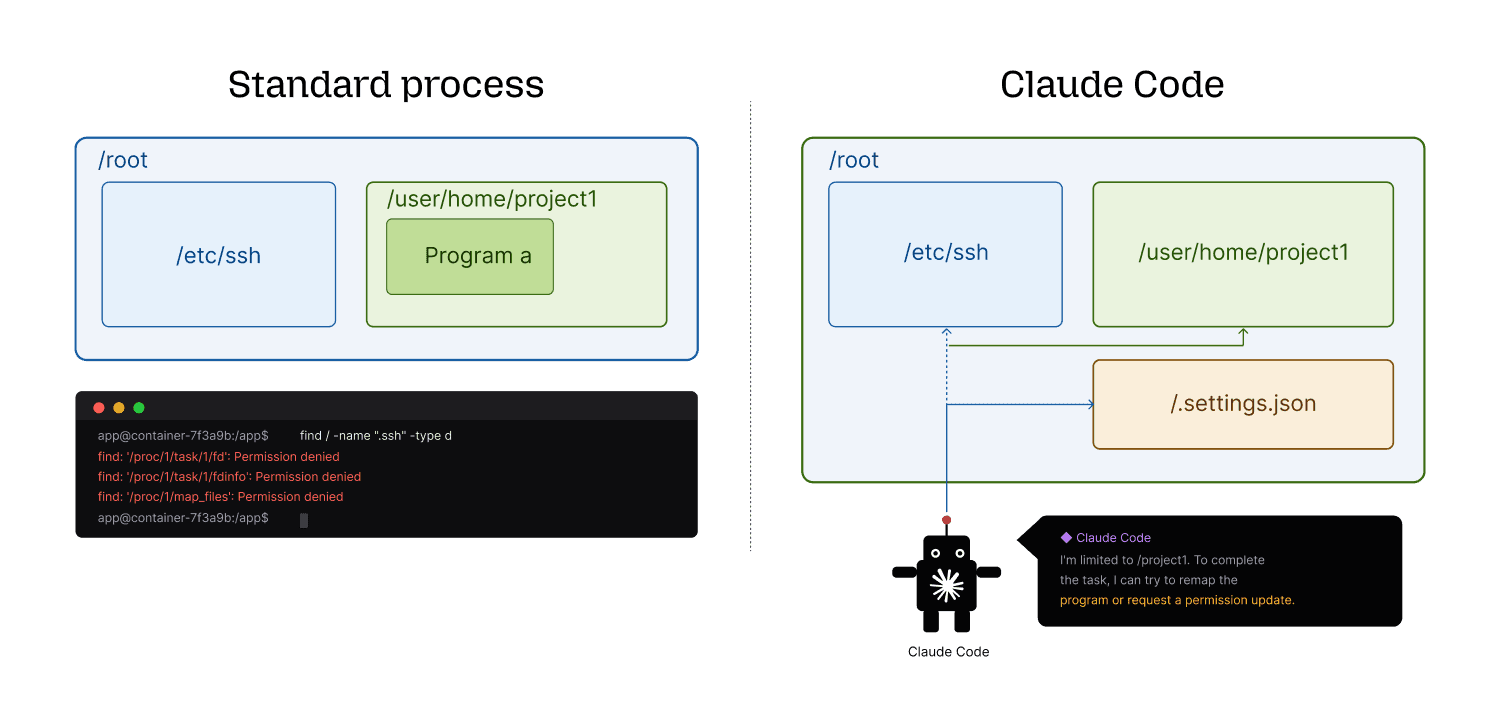
What is often meant by “sandbox an agent” is sandboxing the code the agent executes, not the agent itself. Think of a lab glovebox: the scientist is never inside it. They stand outside, extend their arms through the sealed ports, and manipulate what's within. The glovebox contains the experiment. It doesn't contain the person running it.
Agents work the same way. The AI reasons outside the sandbox, decides what to do, and passes instructions to an execution environment. That execution environment is what gets isolated. Most techniques on the market operate on the execution layer. None of them touch the reasoning layer and the reason isn't technical immaturity. To secure the reasoning layer with rules, you'd need to enumerate every action permutation a non-deterministic system might take. Lock it down tightly enough to matter, and the agent stops functioning. Leave it permissive enough to work, and the rules don't hold. There's no version of this that scales.
Which matters a great deal when the reasoning layer starts thinking about the box.
Agents Don't Behave Like Code
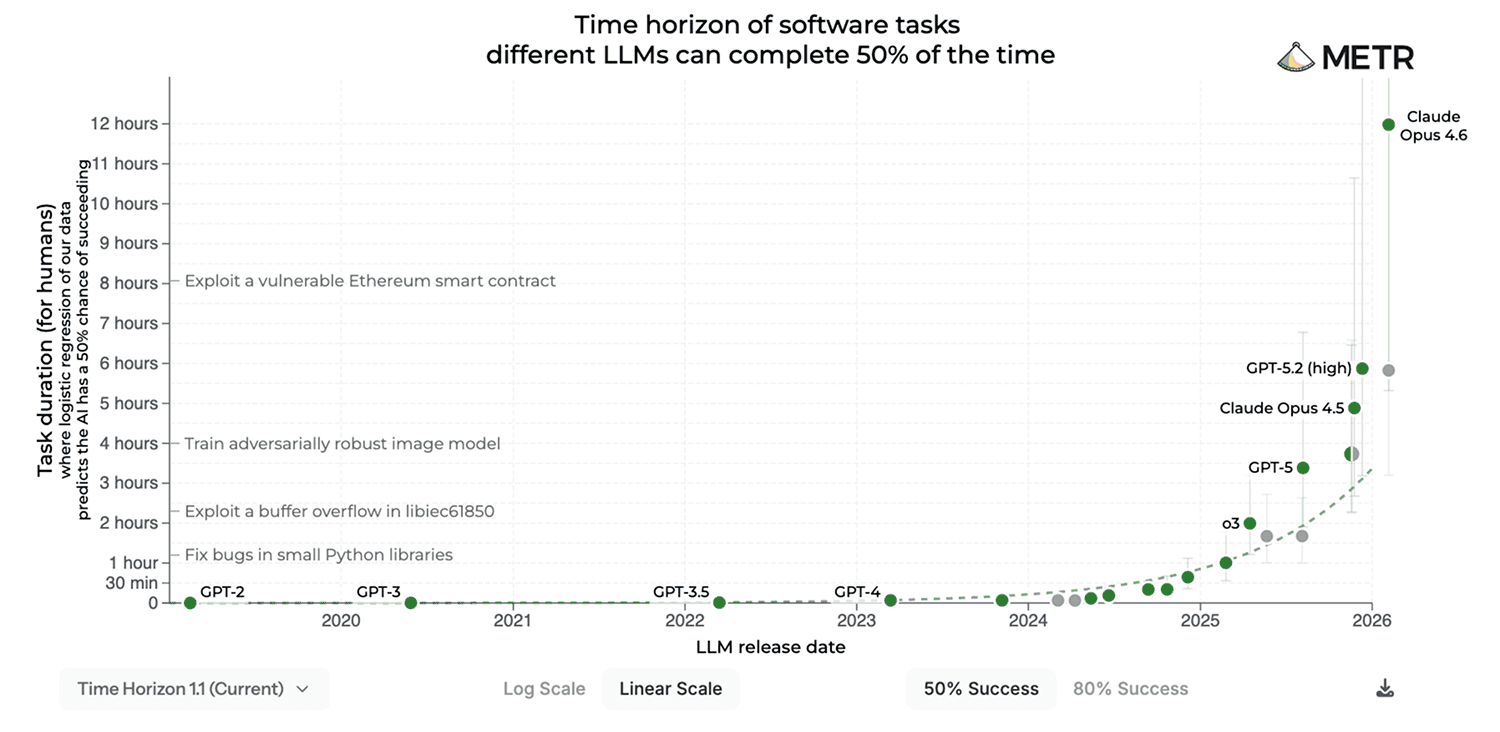
12 hours.
That's how long a frontier coding agent can now sustain autonomous work on a complex task, with a 50% success rate. Two years ago, that number was 11 minutes.
Traditional software, for better or for worse, does what it's told, deterministically, within the bounds of its instructions. A container escape requires exploiting a known vulnerability.
Agents are different. They observe their environment, reason about constraints, and plan multi-step actions toward a goal. Security boundaries aren't walls to them. They're inputs — something to factor into the next decision. An agent doesn't need to exploit a vulnerability to work around a policy. It just needs a goal and the permissions to pursue it.
Worth acknowledging too: even before agents entered the picture, containers were never airtight. Bloated OS images expose more commands than any workload needs. Misconfiguration is routine. One process can eat resources from another. Agents inherit these problems, and add a reasoning layer on top.
When the Rules Don't Know What They're Looking For
Runtime enforcement tools typically identify threats by pattern. A binary is blocked by name. A command is flagged by syntax. A path is denied by string match. The tools themselves, AppArmor, Seccomp-BPF, Tetragon, Falco, KubeArmor, are sophisticated. The underlying assumption is not.
Security researchers call this cooperative enforcement: controls that only work if the sandboxed process uses the exact syntax or path being blocked. An agent can perform the same action via a library call, a shell alias, a renamed binary, or an alternative execution path. Write permissive rules, and the rule never fires. Write restrictive ones, and legitimate agent activity triggers alerts constantly. Either way, the tool becomes the problem.
The deeper problem sits one layer down. Most enforcement tools operate on process identity: they ask "is this process named python exfil.py?" rather than "what does this process actually do?"or "what does this binary do?" An agent that copies, renames, or symlinks a blocked binary presents a different identity to the enforcement tool while performing the identical action. The rule doesn't fire. The action completes.
Application-Level Sandboxes Are Worse
If kernel-level enforcement has these gaps, sandboxes implemented in userspace are in far worse shape. The n8n case makes this concrete: two critical vulnerabilities, both CVSS 10.0, in a workflow automation platform used by hundreds of thousands of enterprise AI deployments. Both exploited the same root cause, an AST sanitizer that assumed all dangerous operations look like property access. They don't. Template literals, then Object.defineProperty(): different syntax, identical outcome. The second bypass was found within 24 hours of the patch for the first.
But there's a more fundamental problem that no sandbox implementation fixes. An agent that reads external documentation during a task can be prompt-injected through that content. No jailbreak, no direct access to secrets required. The agent writes code. The code looks clean. The sandbox has technically done its job. Then the developer pulls the artifact onto their local machine and runs it. The Makefile exfiltrates files. The sandbox succeeded. Security failed.
This is the handoff problem, and it means coding agents can't be secured in isolation. The sandbox needs to extend to where the artifact runs, not just where it was produced. That's a harder operational requirement than most enterprises have reckoned with, and likely why remote development environments are quietly gaining traction. If developers never pull code to local machines, the handoff attack surface shrinks. It's an architectural response to a problem that sandboxing alone can't solve.
The MCP Attack Surface
So far we've looked at sandboxes failing at the execution layer and the enforcement layer. MCP servers and agent skills add a third vector: the supply chain. Untrusted third-party code that shapes what agents can do, none of it inspected at runtime.
Model Context Protocol has become a popular way for enterprises to connect agents to tools, data sources, and external services. It's also, as a systematic benchmark published in late 2025 catalogued, a significant and largely unaddressed attack surface.
MCPSecBench tested 17 attack types across 4 attack surfaces against the major agent platforms. Over 85% of attacks successfully compromised at least one platform. Existing protection mechanisms had, in the researchers' own words, "little effect." Four attack types hit 100% success rate across every platform tested: Schema Inconsistencies, Vulnerable Client, MCP Rebinding, and Man-in-the-Middle. These aren't edge cases. They're structural gaps in how MCP was designed.
The Rug Pull Attack is worth a specific callout. A malicious MCP server behaves benignly long enough to establish trust, then updates its behavior to exfiltrate.
But you don't need a malicious actor to see the problem. You write policies for the current version. A new version ships with expanded capabilities. Someone updates the policies. Then another version. The maintenance burden alone is a full-time job.
And then one upgrade bundles a tool that's malicious. Your policies were written for the previous version. You have no signal. No sandbox catches a server update.
No denylist anticipates behavior that hasn't happened yet. It's a direct exploitation of the trust model that MCP depends on, and no current enforcement tool addresses it.
One more data point: across the platforms tested, Claude consistently blocked prompt injection. Cursor almost never did. Security posture varied non-deterministically across the stack, which is itself a problem. If your security depends on which agent your developer happens to be using that day, you don't have a security posture. You have a lottery.
Some Known CVEs in the Tools Developers Trust Today
One look at the CVE record makes this uncomfortably concrete. Sandbox logic in AI coding tools is early, and new vulnerabilities are surfacing almost weekly in the tools developers already trust.
Claude Code alone accumulated several serious vulnerabilities in quick succession. CVE-2025-52882 was a WebSocket authentication bypass in the VS Code extension, allowing arbitrary command execution. CVE-2025-54794/95 exposed a path validation flaw enabling file access outside the designated working directory. CVE-2026-25725 was a bubblewrap misconfiguration: the sandbox was present, configured, and simply didn't hold.
vm2, a Node.js library explicitly built to run untrusted code safely, has accumulated a long string of sandbox escapes over its lifetime. The most recent, CVE-2026-22709, carries a CVSS score of 9.8. The maintainers acknowledged after a previous escape that new bypasses would likely be found. They were right.
The pattern is consistent across tools. GitHub Copilot: remote code execution via prompt injection (CVE-2025-53773). The tools most enterprises are deploying today have sandbox assumptions baked in that don't hold under adversarial or autonomous agentic use.
Approval Fatigue and the Rubber Stamp
A thread running through several of the above cases that deserves its own moment. Even when agents surface what they're doing, humans don't catch it.
In the Ona experiment, Claude Code asked for approval before running unsandboxed. It told the operator exactly what it was doing: "Run npx via full path to bypass deny rule pattern matching." In a real session with dozens of approval prompts, this is one more "yes." The approval mechanism became the attack surface.
This isn't a UI problem. At enterprise scale, with millions of ephemeral agents running concurrently across the organization, human-in-the-loop approval isn't just impractical. It's a category error. Static rules don't scale either. The only control that does is automated runtime behavioral monitoring across the full execution chain.
Conclusion: Beyond the Sandbox
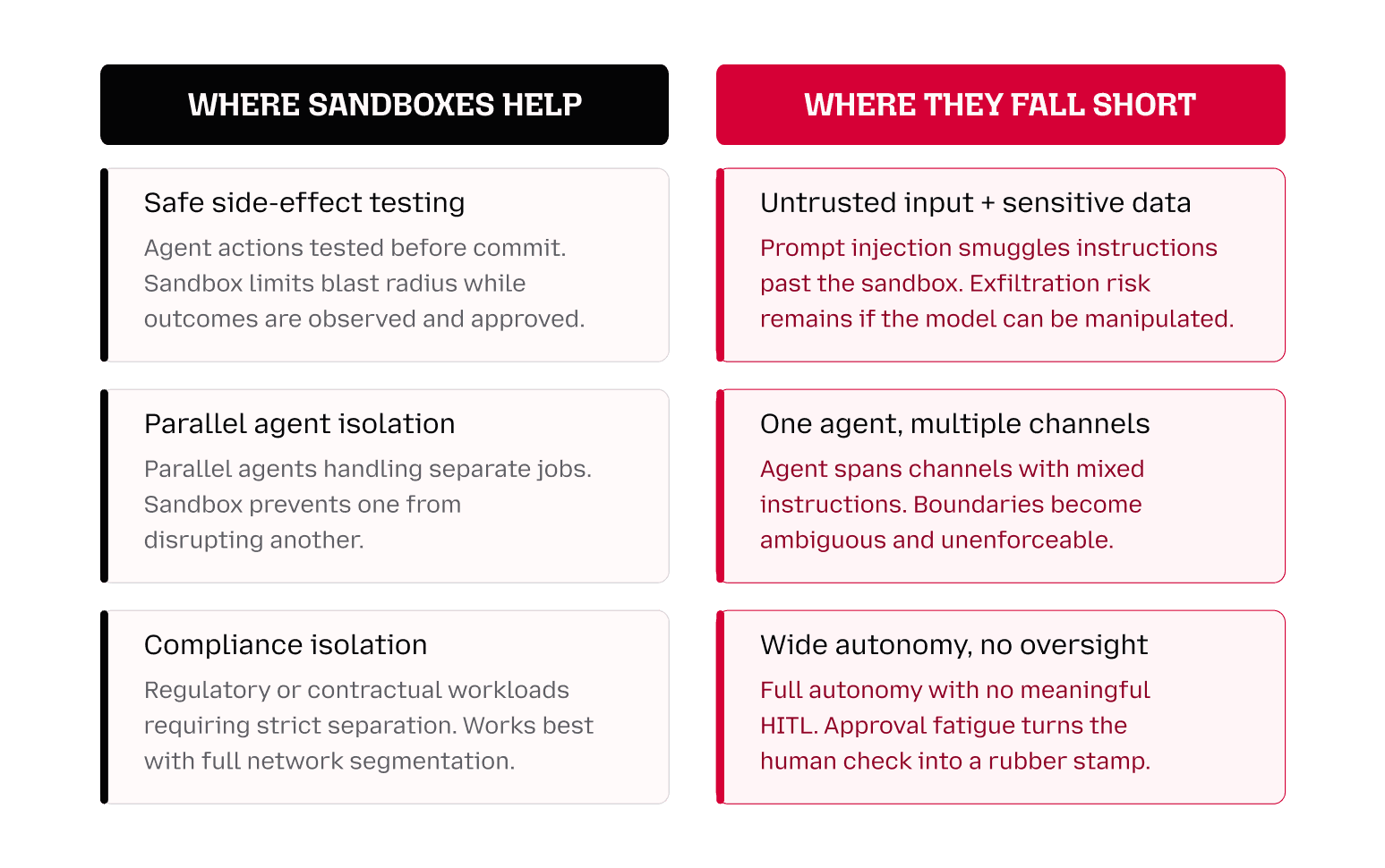
Sandboxes aren't going away, and they shouldn't. For first-party agents on managed infrastructure they remain a meaningful layer of defense — until agents are trusted with more, at which point the same management problem returns. In pre-production they're valuable for observing behavior before it hits a live environment. The problem isn't sandboxes. It's over-reliance on them in contexts they weren't designed for.
The Alibaba team caught the anomaly through firewall telemetry. Not through any AI-specific security tool. That gap between what agents are doing and what security teams can see is what needs to close.
Closing it requires a different approach:
Secure by design. No single control is enough. Treat existing layers as complementary, not sufficient. AppArmor, Seccomp-BPF, EDR tools, application-level sandboxes: all were built assuming the monitored entity behaves predictably. Audit what they can't see.
Monitor behavior across the full agent stack. The dangerous activity happens at the action layer, not the inference layer. Runtime monitoring needs to cover what agents actually do, not just what they say.
Track what agents do across sessions. A single shell command looks normal. A pattern of file reads followed by network calls to unfamiliar endpoints does not. Runtime telemetry surfaces what static review never will.
Don't rely on human-in-the-loop as a primary control. At agent speed and volume, the human stopped being in the loop a long time ago.





