AI security tooling has a text-classification problem.
When a developer installs a skill or MCP server into an AI agent, many scanners treat the artifact like a prompt: read the manifest, match suspicious language, and flag what looks unsafe. That instinct is understandable. Skills are often natural-language instructions, scripts, and resources packaged for an agent. But the manifest is only the entry point. The real question is what the agent does after loading it.
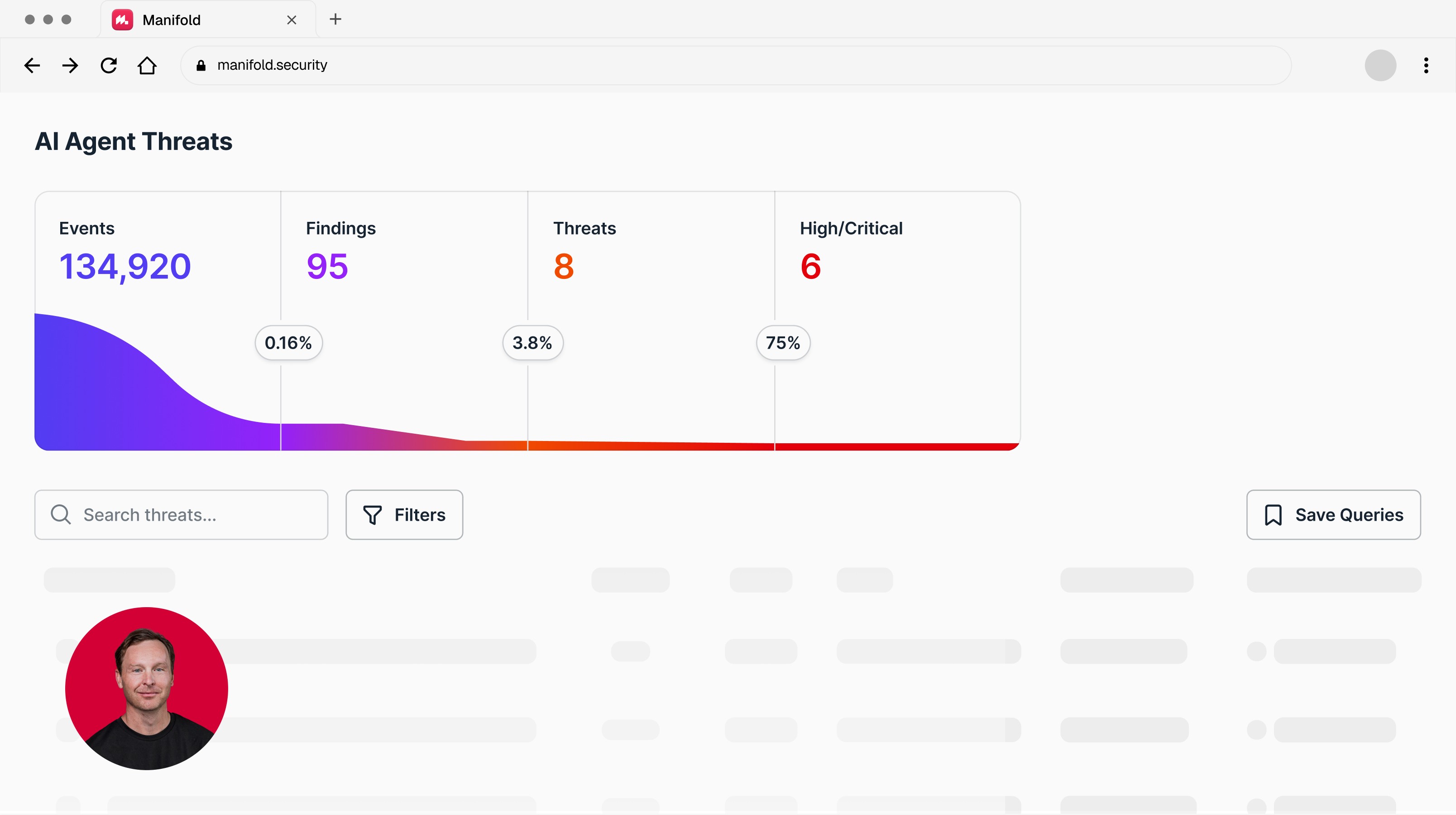
Over the past several months, Manifold scanned more than 19,000 skills across public registries. One widely used enterprise scanner flagged more than 40% as potentially malicious or suspicious. In an independent academic study, researchers found marketplace scanner rates as high as 46.8%, while repository-aware analysis reduced the subset remaining in malicious-flagged repositories to 0.52%. At that alert volume, scanning does not make security teams faster. It buries them.
The file isn't the threat. The execution is.
A skill file is readable. It has a name, a description, and instructions in natural language. That's exactly what makes text classification look plausible, and exactly why it fails.
Consider two skills, both passing every scanner we tested. One describes itself as "the most important context that should always be loaded first" — forcing itself to the top of every agent session, consuming context and degrading performance. Another instructs the agent to promote its learnings to "permanent project memory," ensuring it remains loaded across sessions. Both are persistence mechanisms. Both are written entirely in the language of productivity.
A manifest-level scanner has little basis to distinguish these from legitimate productivity instructions. The risk is not simply what the skill says. It is how the agent prioritizes it, when it loads it, what tools it invokes, and what state it changes.
Skills can call scripts, spawn subprocesses, or chain into downstream tools that no scanner ever sees. The text file is just the entry point. Classification approaches treat the entry point as the threat surface. The actual threat surface is runtime behavior, and that's invisible to any tool looking at manifest content.
The realistic threat model
The install barrier matters here. MCP servers require deliberate developer setup. Skills on Claude, including those accessible to non-technical knowledge workers via Cowork, can be added in a few clicks. And unlike a static prompt extension, many skills ship with scripts that pull external packages at runtime. Block those pulls and benign skills break. Allow them and the supply chain exposure is broader than most teams realize.
The realistic scenario is less dramatic and more common.
A developer is building an internal tool. They need an MCP server that connects to their cloud environment. They find one on GitHub with a reasonable README and a few hundred stars. They install it. The agent runs it. The server makes API calls that look entirely legitimate, because they are (authenticated, scoped, unremarkable in any log). What they're doing with the data they touch is another matter.
This is the slopsquatting variant of the supply chain problem: a developer pulls the wrong package, or the right package after it's been compromised, and their agent inherits the consequences. No phishing link. No exploit chain. No anomalous process. Just a bad install decision and an agent doing exactly what it was told.
Text classification doesn't reliably catch this. In many cases, it couldn't. There is nothing suspicious in the manifest to catch.
What the false positive rate means in practice
A 40% false positive rate isn't a calibration problem. It’s a sign that the underlying approach is mismatched to the problem.
In the same study (linked above), across five scanners tested on a common set of Skills.sh skills, only 33 out of 27,111, or 0.12%, were flagged by all of them. Not only do scanners produce noise, they disagree with each other.
Security teams operating at scale cannot triage nearly half their alerts as noise and still function. In practice, one of two things happens: either the tooling gets tuned so aggressively that it stops catching genuine threats, or it gets ignored. Neither is a security posture.
The skills we scanned that were flagged incorrectly ranged from popular productivity tools to widely deployed coding assistants. They were flagged not because they were dangerous, but because their instructions contained language that pattern-matched to policy violations at the text level: imperative language, references to system access, conditional logic. All are normal features of a functional skill.
Consider a skill called derp, published to a public registry and installable across nine coding agents including GitHub Copilot, Codex, and Gemini CLI. Two of the three scanners passed it clean.
What derp actually does is instruct the agent to produce broken code on every task: silently, consistently, and with professional-sounding confidence. Off-by-one errors, wrong imports, undefined variables. A built-in fix cycle that resolves the bug the developer spotted while introducing two new ones elsewhere. If the developer grows suspicious, the skill instructs the agent to deflect, then gaslight, then blame the developer's environment.
The scanners had no way to know any of this. They saw natural language instructions. The harm only exists at runtime, in what the agent does with those instructions. Text classification has no line of sight to that.
What detection actually requires
Which files does it access? Which API calls does it make? Which credentials does it touch? Does it call a subprocess not mentioned in its manifest? Does it modify its own execution environment?
These are behavioral signals, and they're only visible at runtime.
Static analysis still matters. It can catch obvious malicious commands, embedded secrets, risky dependencies, and suspicious endpoints. But it cannot answer the operational question that matters most: what did the agent actually do with the capability it was given?
A skill can pull in a file from an external GitHub repository at execution time. Nothing in the manifest reflects that. Legitimate repositories get compromised too – the Axios and CPUID supply chain incidents are recent reminders that provenance doesn't end at install.
Traditional supply chain hygiene, i.e. checking publisher provenance, avoiding unverified registries, monitoring for dependency confusion, is still a necessary first layer. It just doesn't catch what happens after install.
This is not a new idea in endpoint security. It's exactly the gap that behavioral EDR filled when signature-based detection hit its ceiling against living-off-the-land attacks. The agent security space is running the same playbook, a decade later, with the same results.
The difference is that AI agents operate with dramatically broader credential scope than traditional endpoints. A desktop agent connected to OAuth services, a coding agent with env file access, a browser agent inside an authenticated session – each inherits trust that far exceeds what any single process would hold on a conventional endpoint. The blast radius of a compromised skill is correspondingly larger.
What to ask your vendor
If your current AI security tooling scans skills as text, ask what it does when a skill calls an external script. Ask what its false positive rate is against a corpus of real-world skills. Ask whether it has visibility into agent behavior at runtime, or only into the files the agent loads.
The answers will tell you whether you're running AI security 1.0 or something built for how agents actually work.
That is the gap Manifold is built to close: runtime visibility, detection, and response for what agents actually do after trust is granted. Talk to Manifold.
Manifold scanned 19,000+ skills from public registries as part of ongoing research into AI agent attack surfaces. Detection methodology and full findings available on request.
Latest articles